Sont-elles uniques...?

Je parle de valeurs dans les couches SIG, voyons comment les lister ?
Attaquons-nous au contenu des données. Comme tout le monde, ou presque, vous vérifiez vos données, ou lors de la récupération de couches extérieures, on se doit de vérifier le contenu des colonnes pour savoir à quoi s'attendre.
Je vous propose de travailler dans QGIS (3.16 pour moi) et dans POSTGRESQL (11 sur mon PC) pour lister tout ça.
C'est quoi une valeur unique ?
J'enfonce sûrement un porte ouverte mais soyons d'accord sur la définition. Il s'agit de valeurs distinctes dans une colonne de données. C'est donc la liste de toutes les valeurs vues au moins 1 fois et sans doublons. Exemple
| Ukrainiens |
| Soutien |
| Soutien |
| Soutien |
| Ukrainiens |
| aux |
La liste de valeurs uniques sera : Soutien, aux, Ukrainiens (message habilement dissimulé, n'est ce pas ?)
Hors l'on sait que pour la machine, la moindre différence va se voir. Soutien n'est pas soutien (la majuscule), Monsieur n'est pas Mnosieur. Il peut donc être important de lister les données des colonnes pour vérifier la propreté des données ou savoir comment cela a été saisis. Voyons différentes méthodes.
Les données d'exemple
Je prend quelques données un peu au hasard, c'est à dire, quelques 216 communes les plus au nord de la France (source Admin-express de l'IGN).
La table est construite comme suit :
| ID | NOM | NOM_M | INSEE_COM | STATUT | POPULATION | INSEE_CAN | INSEE_ARR | INSEE_DEP | INSEE_REG | SIREN_EPCI |
| COMMUNE_0000000009726969 | Armbouts-Cappel | ARMBOUTS-CAPPEL | 59016 | Commune simple | 2240 | 12 | 4 | 59 | 32 | 245900428 |
| COMMUNE_0000000009727048 | Arnèke | ARNEKE | 59018 | Commune simple | 1594 | 41 | 4 | 59 | 32 | 200040947 |
| COMMUNE_0000000009727175 | Bailleul | BAILLEUL | 59043 | Commune simple | 15019 | 08 | 4 | 59 | 32 | 200040947 |
Nous verrons donc combien de valeurs uniques nous allons trouver.
Avec un plugin
Il existe dans l'excellent site de Géoinformations et notamment en installant la liste de plugin (pour cela aller dans extension - gérer/installer les extensions - paramètres - ajouter... l'adresse suivante :
http://piece-jointe-carto.developpement-durable.gouv.fr/NAT002/QGIS/plugins/plugins.xml )
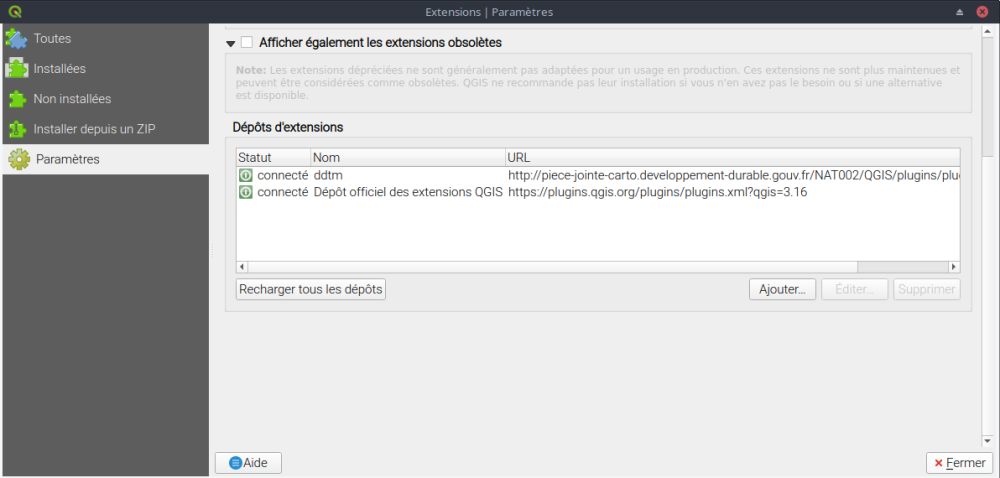
Dans la liste des plugins, vous avez désormais ValeursUniques. Une fois installé, voyons son fonctionnement.
Pour le trouver, il faut aller dans la boîte de traitement, puis dans les outils GSG DRC - liste des occurrences (oui le nom est différent que celui du plugin)

Le truc est qu'il faut absolument indiquer un fichier en sortie avec .csv, sinon il y aura une erreur.
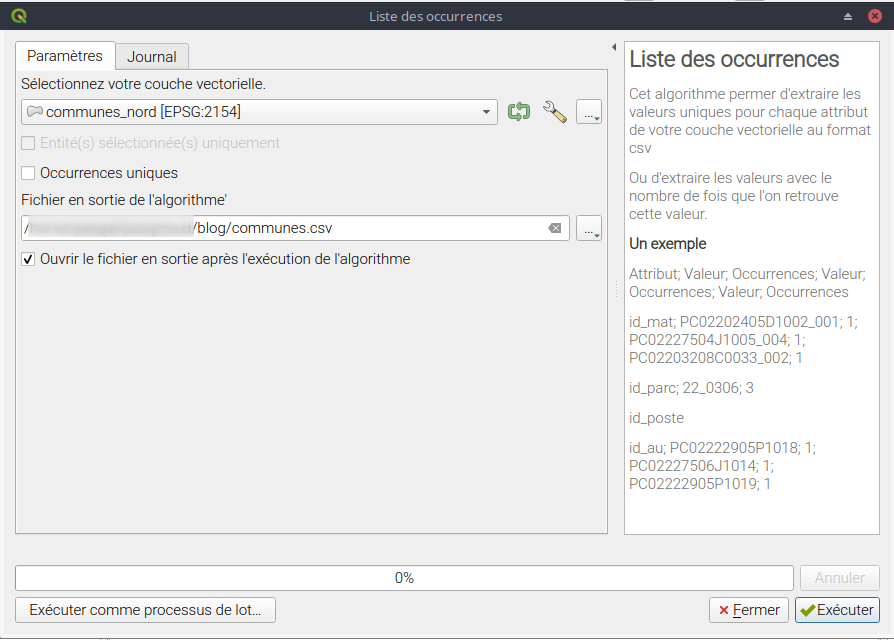
La sortie donne un fichier .csv, que l'on peut ouvrir dans un tableur (séparateur ";") . Chaque ligne reprend le nom des colonnes, et les colonnes listent les "occurrences".
Par exemple, ici pour lire le fichier :
- dans la ligne ID, j'ai 216 colonnes indiquant la valeur ID et occurrence 1 : ce qui est normal pour un identifiant
- si je regarde la ligne STATUT, j'ai 212 "commune simple"; 4 "Sous-préfecture" et, comme il n'y a plus de valeurs dans les autres colonnes de la ligne, il n'y a pas d'autre occurrence.
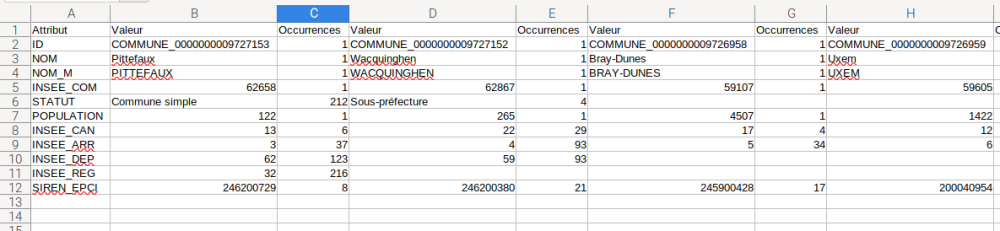
Donc voilà, j'ai ma liste, si vous cochez la case "occurrences uniques" dans les paramètres, le tableau ne vous présentera que les valeurs avec une occurrence 1 (mais pas les autres valeurs).
Script python
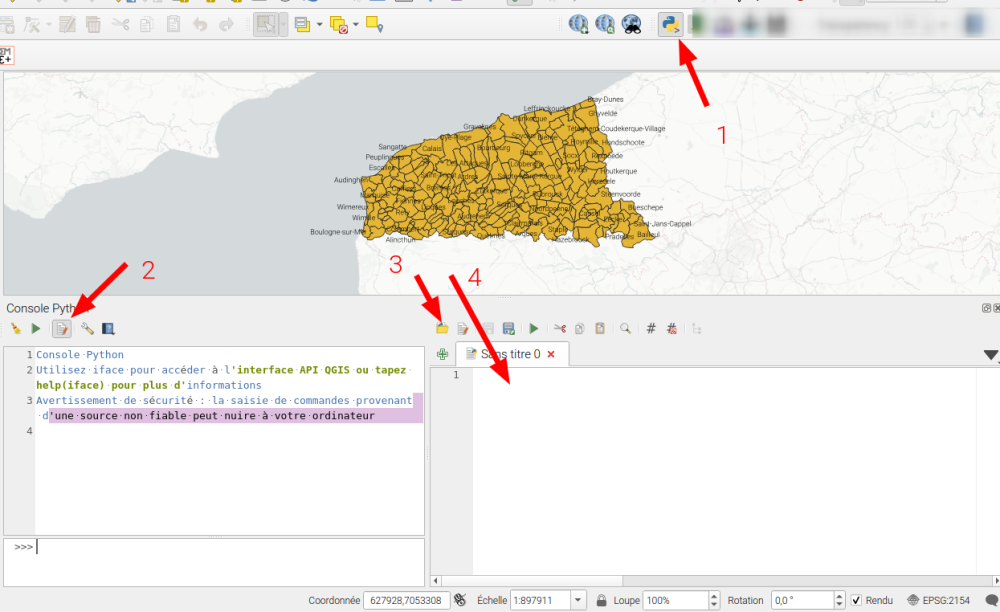
Regardons pour automatiser la liste et le comptage avec un script python. Alors rappel, pour utiliser un script, on ouvre la console (1), puis ouvrir l'éditeur (2), et soit nous ouvrons un fichier(3), soit nous saisissons dans l'éditeur (4) et là un copier-coller avec le code peut fonctionner. N'oubliez pas d'enregistrer votre script.
Le script est le suivant ( ou à télécharger ici )
| from qgis.core import * import qgis.utils layer=qgis.utils.iface.activeLayer() fields=[] # List of fields Lquery=[] # List of queries to join together with Union All statement Cquery=[] # Combined Query to use for field in layer.fields(): # ATTENTION à changer le nom de l'identifiant pour éviter liste trop longue if field.name() not in ('ID'): fields.append(field.name()) query = " Select '{0}' as 'Champs', CAST({0} AS text) as 'Valeur', count(*) as 'Unique' from {1} group by {0} having count(*)!=1".format(field.name(), layer.name()) Lquery.append(query) else:( print (field.name()) for L in Lquery: Cquery.append(L+' Union All ') query=''.join(map(str, Cquery)) query=query[:-11]+' Order by Champs' vlayer = QgsVectorLayer( "?query={}".format(query), 'counts_'+layer.name(), "virtual" ) QgsProject.instance().addMapLayer(vlayer) |
Après les imports des outils QGIS, sont définis des tableaux permettant le stockage des infos (champs, requêtes...) Pour chaque champ de la couche : Je teste et je retire les identifiants qu'il faut saisir pour éviter les champs forcément unique du type, ID, pk_machin... bon, il faut les connaître, mais cela évites les longues listes. Sinon, si vous voulez vraiment les valeurs autes que unique, on ajoute having... Vous pouvez retirer cette partie en jaune pour avoir toutes les valeurs. Ensuite la requête est composé d'un SELECT en sql où les champs et couches sont remplacés par les valeurs issues de la couche indiqué en {0} et {1} (les variables) Cette requête se concatène dans une requête géante, liée par UNION ALL Ensuite, on génère une couche virtuelle qui commence par "count_"+ le nom de la couche. La requête de cette couche virtuelle étant la requête géante.
|
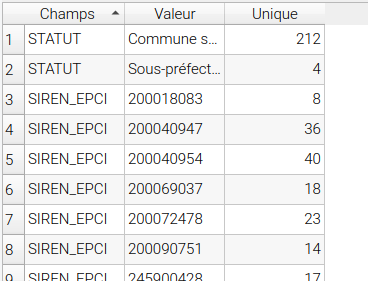
Ensuite, lancer le script, une couche virtuelle est créée. Dans mon exemple, en ouvrant la table attributaire de count_communes_nord, je peux lire le résultat
- Le champ STATUT contient 212 "Commune simple", et 4 "Sous-préfecture"
- SIREN_EPCI contient 8 fois 200018083, etc etc
// vous noterez ici que j'ai utilisé le code avec having count(*)!=1, je n'aurai donc pas les valeurs présentes 1 seule fois.
Dans POSTRESQL/POSTGIS
Pour ceux qui ont la chance de pouvoir travailler dans une base de donnée POSTGRESQL (et accessible). On peut créer une fonction qui aide à compter les valeurs.
Alors pour cela, créons la fonction (à télécharger ici), dans votre pgAdmin ou Dbeaver ou autre :
|
CREATE OR REPLACE FUNCTION public.aa_get_count( TEXT, TEXT, BIGINT) BEGIN SELECT STRING_AGG( 'SELECT ''' IF v_sql_statement IS NOT NULL THEN |
nous créons donc une fonction avec 3 variables en entrée : nom du schema, nom de la table, un compteur cette variable retourne (RETURNS) 3 choses : le nom de colonne, les valeurs, et leurs comptes après les déclarations des variables pour Plpgsql, on commence : on va agréger une requête sql (du type pour trouver les doublons), on remplace juste les noms par les variables. on cherche ces infos dans la table informations_schema (qui contient le nom des tables avec le nom des colonnes dans POSTGRESQL). on vérifie qu'il y a des infos (IF) et on exécute la requête agrégée.
Votre fonction est créée et utilisable à l'infini. |
| select c.colonne, c.valeur, c.compteur from public.aa_get_count( 'public', 'communes_nord',0 ) as c(colonne,valeur,compteur); |
Pour l'utiliser, dans votre requêteur SQL préféré, remplacer 'public' par votre schéma et 'communes_nord' par le nom de votre table, le zero est obligatoire pour respecter le nombre de variables. |
Pour le test, j'ai importé ma couche de test, et j'ai lancé :
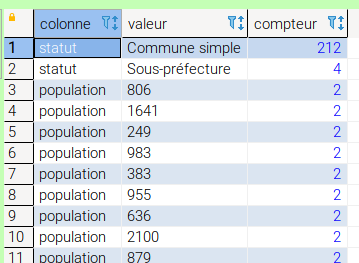
On a donc bien la liste des occurrences. Vous remarquerez que j'ai encore mis un HAVING count(*)>1 pour ne pas sortir les occurrences uniques. Si vous le supprimer de votre fonction, vous aurez toutes les valeurs même celles qui n'apparaissent qu'une fois (on peut faire 2 fonctions aussi avec et sans le having).
Voili, voilou
Si maintenant, vous n'arrivez pas à faire dans la data quality, alors je n'y suis pour rien. Un cas de question ou d'optimisation possible, n'oubliez pas de le mettre en commentaire. Et faîtes tourner, cela peut servir à des amis ou dans une soirée où on s'ennuie...